海量、多源的遥感影像为城市规划、资源监测、灾害应急等应用任务提供了数据基础,然而,现有遥感影像解译研究主要集中在从遥感影像中获取地物目标的位置与类别信息,难以进一步形成决策知识。如何将遥感影像转换为语言文本是其中的关键难题。为此,测绘遥感信息工程国家重点实验室马爱龙和钟燕飞牵头的RSIDEA研究团队近年来围绕这一问题,从多模态遥感视觉-语言推理基准数据集到基准模型进行了逐步探索研究,在人工智能会议AAAI 2024和遥感一区TOP期刊ISPRS Journal of Photogrammetry and Remote Sensing上连续发表相关成果。
成果“EarthVQA: Towards Queryable Earth via Relational Reasoning-Based Remote Sensing Visual Question Answering”(EarthVQA:通过遥感关系推理视觉问答迈向可查询的地球视觉)发表于人工智能顶级会议《Proceedings of the AAAI Conference on Artificial Intelligence》,武汉大学测绘遥感信息工程国家重点实验室博士研究生王俊珏为第一作者,钟燕飞教授为论文的通讯作者。
RSIDEA研究团队构建了遥感影像视觉问答基准数据集EarthVQA,EarthVQA基准数据集包含6000幅0.3米高分辨率遥感影像数据与地表覆盖标注,基于多样性的地学应用任务需求,进一步标注208593个问答样本对。如图1所示,EarthVQA问答对包括基础判断、基础计数、基于关系推理判断、基于关系推理计数、地物状态分析、综合分析等内容,涉及了复杂的地物空间与语义关系(如居民区内的绿化、农田周围的水源等),EarthVQA基准数据集是目前最为复杂的遥感视觉-语言推理数据集

图1. 遥感影像视觉问答基准数据集EarthVQA
成果“EarthVQANet: Multi-task Visual Question Answering for Remote Sensing Image Understanding”(EarthVQANet:遥感影像理解的多任务视觉问答基准模型)发表于遥感领域顶级期刊《ISPRS Journal of Photogrammetry and Remote Sensing》,武汉大学测绘遥感信息工程国家重点实验室博士研究生王俊珏为第一作者,马爱龙副教授为论文的通讯作者。
RSIDEA研究团队建立了遥感影像多任务视觉问答基准模型EarthVQANet。针对EarthVQA数据集特性,进一步设计了遥感影像多任务视觉问答基准模型,EarthVQANet基准模型如图2,多尺度金字塔语义分割制图网络获取地表覆盖制图结果,为视觉问答任务生成像素级视觉特征和地物对象语义引导,实现精准空间语义关系推理;语义分割网络与视觉问答模型通过多任务学习策略,相互促进特征表示学习,同时实现高分辨率遥感地表覆盖信息抽取与决策推理,以语言文本的形式,从交通情况、教育设施、绿化生态、耕地状态、灾害应急等方面提供多样化决策建议。
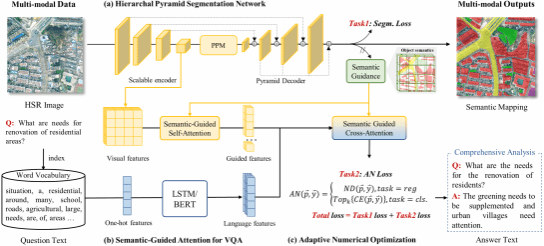
图2. 遥感影像多任务视觉问答基准模型EarthVQANet
相关论文信息:
[1] J. Wang, Z. Zheng, Z. Chen, A. Ma, Y. Zhong. EarthVQA: Towards Queryable Earth via Relational Reasoning-Based Remote Sensing Visual Question Answering. Proceedings of the AAAI Conference on Artificial Intelligence [C], vol. 38, pp. 5481-5489, 2024
[2] J. Wang, A. Ma, Z. Chen, Z. Zheng, Y. Wan, L. Zhang, and Y. Zhong, "EarthVQANet: Multi-task visual question answering for remote sensing image understanding," ISPRS Journal of Photogrammetry and Remote Sensing [J], vol. 212, pp. 422-439, 2024
EarthVQA数据集下载地址:http://rsidea.whu.edu.cn/EarthVQA.htm

