(通讯员:涂志刚、姚远)测绘遥感信息工程全国重点实验室涂志刚团队最新研究成果Visual Prompting for One-shot Controllable Video Editing without Inversion被国际计算机视觉顶级会议CVPR2025(CCF A类会议)录用在线发表。张正博博士和周誉喜硕士为共同第一作者,涂志刚研究员为通讯作者。
在本成果中,研究团队提出了一种基于视觉提示 (Visual Prompting) 的新型一次性可控视频编辑 (OCVE) 框架,旨在规避传统DDIM反演带来的误差累积问题。该框架依赖于一个预训练的图像修复扩散模型 (Image Inpainting Diffusion Model) 来执行编辑传播。具体来讲,研究团队将OCVE任务重构为视觉提示:这是因为视觉提示和一次性可控视频编辑的共同目标是在图像间传播某些修改。如图1所示,在视觉提示中,示例中所做的修改(例如,将山的颜色从金色改为绿色)会转移到视觉提示的query中,而在一次性可控视频编辑中,对第一个编辑帧应用的修改会传播到后续源帧。此外,研究团队通过精心设计的输入信息G (包含首帧源/编辑对作为示例,后续源帧作为查询)、掩码M(指定编辑区域)以及基于CLIP特征差计算的编辑方向提示p,引导修复模型理解并应用编辑意图至查询帧,从而在无需反演的情况下生成编辑结果,具体参见图2。
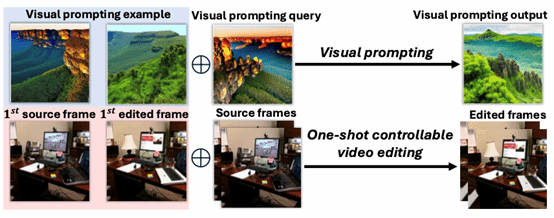
图1. 一次性可控视频编辑(OCVE) 的流程 vs. 视觉提示 (visual prompting)

图2. 本方法输入到预训练的图像修复扩散模型中的数据格式
为进一步提升编辑质量,如图3所示,本成果框架集成了两种关键的采样机制:
首先,研究团队引入了一种内容一致性采样 (Content Consistency Sampling, CCS) 机制,其灵感源于一致性模型,用于保证生成帧与源帧的内容高度一致。CCS通过修改修复模型的采样过程,并引入噪声校准项来逐步引导生成内容从源帧向目标编辑过渡,此过程无需额外训练。
其次,研究团队设计了一种时序-内容一致性采样 (Temporal-Content Consistency Sampling, TCS) 方法,在CCS之后执行,以确保编辑后视频帧间的时序连贯性。TCS基于Stein变分梯度下降 (SVGD),将视频帧视为样本点,在保持内容一致性的前提下,通过优化更新过程并利用核函数显式维持样本间的时序依赖关系,生成时序平滑的编辑视频。
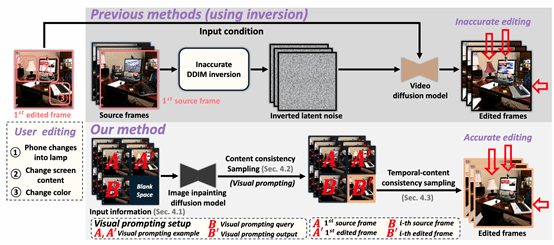
图3. 本方法的具体流程图
研究团队在基于MagicBrush构建大规模数据集上进行了广泛实验,且与Videoshop、AnyV2V等众多当前最先进的方法及多种文本驱动视频编辑方法进行了比较。
如表1所示,研究团队在编辑保真度 (CLIP_tar, TIFA)、源内容保持度 (CLIP_src, Flow, FVD, SSIM) 和时序一致性 (CLIP_TC) 等多项关键指标上均取得最佳性能。此外,研究团队提出的方法在处理速度显著快于依赖视频扩散模型的其他OCVE基线方法。
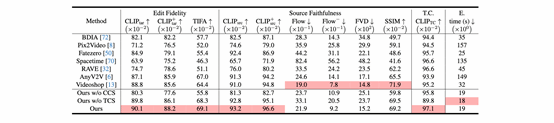
表1. 研究团队方法和当前最先进的一次性可控视频编辑方法的对比
最后,如图4所示,视觉效果对比清晰展示了研究团队的方法在对象替换、移除/添加等复杂编辑场景下的优越性,编辑结果更自然、一致性更强。

图4. 研究团队的方法和其他方法的可视化对比
本成果首次提出将one-shot可控视频编辑视为视觉提示任务,从根本上避免了DDIM反演及其固有缺陷,创造性地发掘并利用了图像修复模型在复杂视觉推理任务(如视频编辑)中的潜力,设计了一种无需训练的内容一致性采样方法,巧妙利用修复模型和一致性采样思想,提升编辑保真度,引入基于SVGD的时序-内容一致性采样,高效地解决了编辑过程中的时序连贯性问题,提升可控视频编辑的实用性与效果。
研究团队介绍:武汉大学-行为理解与视觉感知实验室(HUVPR-Lab),主要研究方向:计算机视觉、视频理解,聚焦视频人体行为识别、重建与生成。
论文下载链接:https://cvpr.thecvf.com/virtual/2025/poster/34729





