武汉大学测绘遥感信息工程全国重点实验室涂志刚研究员与StepFun、字节跳动联合团队的最新研究成果MikuDance: Animating Character Art with Mixed Motion Dynamics 被计算机视觉顶级国际会议 ICCV2025(CCF A类会议)录用为Oral presentation。张嘉旭博士为论文第一作者,涂志刚研究员为论文通讯作者。
研究针对当前静态数字人角色立绘图像动画生成领域存在的高动态动作难控制、角色与动作参考不匹配等核心问题,提出了一个创新性的扩散模型动画生成框架MikuDance。该框架能够将任意风格的角色图像驱动为高质量、高动态一致性的视频动画,兼顾前景人物动作与背景场景运动的协调性。在游戏、动画、影视和数字设计等领域,将静态角色立绘图像生动地“动起来”一直是重要而富有挑战性的任务。传统动画软件(如 MikuMikuDance、Live2D)虽然功能强大,但需要专业动画技能,门槛高且耗时长。近年来,基于扩散模型的图像动画生成方法(如 Animate Anyone、DISCO)成为热点,但这些方法主要针对真实人物和静态背景,无法直接应对角色立绘动画的两大难点:
1. 高动态运动建模困难。角色MMD视频往往伴随大幅舞蹈动作与复杂背景,同时还有相机快速移动(例如舞台镜头推进、旋转等),需要同时建模前景角色与背景场景的高动态变化。现有方法大多只处理静态背景或简单人物动作,缺乏全局动态控制能力。
2. 角色与动作参考错配。动画中的角色可能有夸张比例(如头身比)、不同画风(赛璐璐、古风、线稿等)以及多样服饰,这些都可能与驱动动作视频的姿态、尺度不一致。传统方法依赖显式对齐或预处理,不仅复杂,而且在艺术风格角色中往往失效。
为解决上述问题,研究团队提出了全新的MikuDance动画生成框架,引入两项核心技术:混合运动建模(Mixed Motion Modeling)与混合控制扩散(Mixed-Control Diffusion),并结合运动自适应归一化(Motion-Adaptive Normalization, MAN) 模块,实现对角色与背景的统一高动态控制,具备以下特点:
1. 混合运动建模(Mixed Motion Modeling)。MikuDance首次在二维像素空间统一建模角色局部动作与场景全局运动。核心是场景运动跟踪(Scene Motion Tracking, SMT)策略,它将驱动视频中的三维相机轨迹映射到像素级运动场,形成与角色姿态类似的全局背景运动指导信号。与传统直接用光流或相机参数不同,SMT通过三维点云跟踪消除了内容依赖性,使背景运动控制更稳定自然。
2. 混合控制扩散(Mixed-Control Diffusion)。针对角色与动作参考的形态和尺度错配问题,研究团队将参考角色图像、角色姿态、场景运动同时编码到统一隐空间,避免了多网络独立处理导致的对齐误差。该设计保留了模型架构的简洁性,同时在复杂场景中依然能够精准驱动角色动作。
3. 运动自适应归一化(Motion-Adaptive Normalization, MAN)。为了将全局背景运动自然注入到生成过程中,团队设计了MAN模块,通过空间感知归一化方法在像素级调整特征分布,实现背景与角色动作的无缝融合。
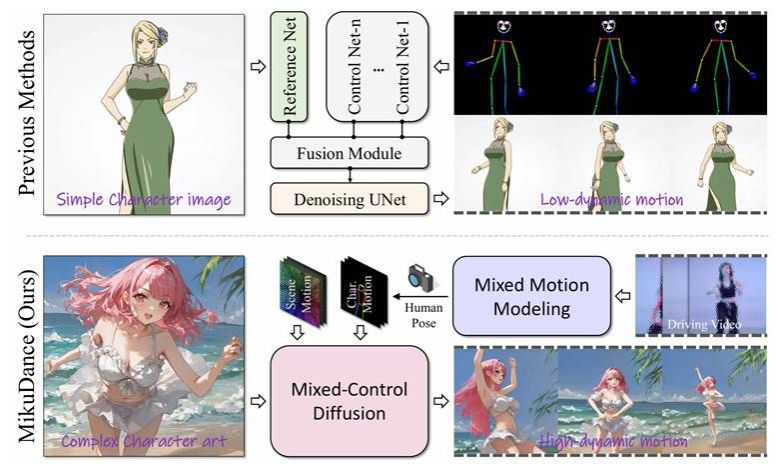
图1 MikuDance模型
如图2所示,混合运动建模(Mixed Motion Modeling)通过场景运动跟踪策略(Scene Motion Tracking, SMT)将三维相机轨迹转化为像素级运动场,从而实现对背景场景的精细控制,避免了传统方法中背景畸变或失真的问题。
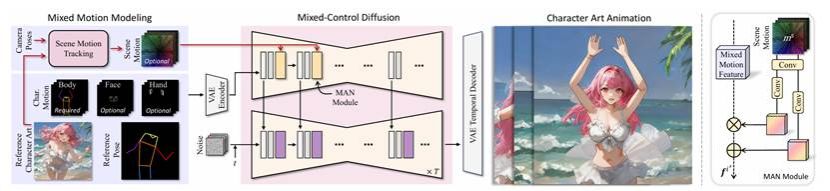
图2 MikuDance动画生成流程图:从角色图像出发,融合动作与相机运动,生成高动态一致的动画序列。
为解决角色图像与驱动动作之间存在的尺度、姿态和形态错配问题,研究团队提出了混合控制扩散(Mixed-Control Diffusion)模块,并引入运动自适应归一化(Motion-Adaptive Normalization, MAN)技术。该机制无需显式对齐,通过将参考图、姿态序列与背景运动编码进统一隐空间,引导扩散模型在生成过程中自适应地融合局部与全局运动,极大提升了动画连贯性与自然度。
MikuDance采用双阶段混合源训练(Mixed-Source Training),以增强模型对不同画风与动态场景的泛化能力。团队构建了一个包含3600段MMD动画视频、约1020万帧的大规模数据集,并在实验中额外引入了约3500段相机运动视频以丰富背景动态样本。
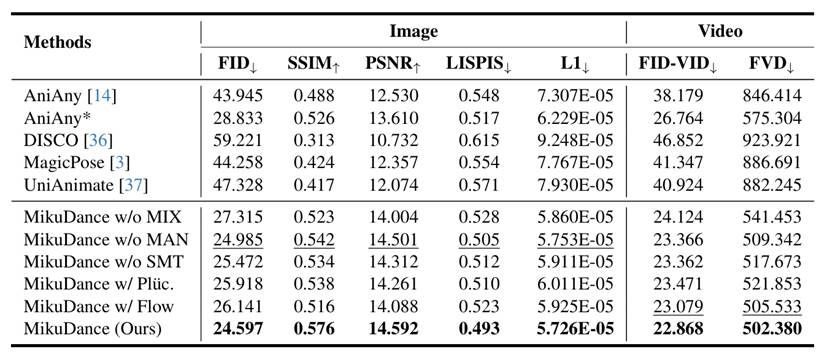
在大规模MMD视频数据集上,研究团队对MikuDance与Animate Anyone、DISCO、MagicPose、UniAnimate等多种SOTA方法进行了系统对比。
如表1所示,MikuDance在FID(图像保真度)、SSIM(结构相似性)、FVD(视频一致性)等关键指标上全面领先。例如,在高动态场景下,MikuDance的FID降低至 24.60,FVD降低至 502.4,显著优于最佳对比方法(AniAny:FID=28.83, FVD=575.3)。在主观用户评测中,超97%的用户更偏好MikuDance生成的视频。
表1 MikuDance与其他方法在图像和视频对象实验结果对比
此外,在高动态舞蹈动作、大幅相机运动、不同体型角色等复杂任务中,MikuDance依然保持了优异表现,如图3所示。

图3 与主流方法在高动态舞蹈动作下的可视化对比,MikuDance在姿态准确性与背景一致性方面优势明显
MikuDance主要创新点为:
1.混合运动建模:首次将角色与相机运动统一表达于二维像素空间,增强了动画时空一致性。
2.混合控制扩散机制:避免传统对齐机制,通过隐式融合参考图与动作信息,提升动画自然度。
3.运动自适应归一化模块:以像素级方式注入背景运动,提高全局动态控制能力。
4.混合多源数据训练机制:结合风格化视频与纯相机运动视频进行双阶段训练,增强泛化能力。
研究团队介绍
本成果由武汉大学行为理解与视觉感知实验室(HUVPR-Lab)牵头完成,团队致力于“以人为中心”的视频行为识别与生成研究。项目主页:https://kebii.github.io/MikuDance
论文下载链接:
https://arxiv.org/abs/2411.08656





